Los conjuntos de caracteres, también llamados juegos de caracteres en castellano, y en inglés CHARACTER SET son todos los caracteres que pueden ser guardados en una columna de tipo CHAR o VARCHAR. Dentro de un conjunto de caracteres a cada carácter se le asigna una posición que será siempre la misma en ese conjunto de caracteres. Por ejemplo, en el conjunto de caracteres ASCII la letra A mayúscula siempre se encuentra en la posición 65.
El conjunto de caracteres base es el llamado ASCII (American Standard Code for Information Interchange, código estándar norteamericano para el intercambio de la información), pronunciado áski, está compuesto por todas las letras mayúsculas, y minúsculas del alfabeto inglés, todos los dígitos, y algunos caracteres especiales. Usa los últimos 7 bits de un byte y por lo tanto tiene 128 caracteres (ya que 2 elevado a la 7ª potencia es 128).

Captura 1. Si haces clic en la imagen la verás más grande
Este conjunto de caracteres es muy bueno … si todo el texto estará escrito en inglés moderno. Pero si quieres escribir texto en español, en portugués, en francés, en chino, en vietnamita, etc., no te servirá porque te faltarán caracteres, en el caso de escribir texto en español encontrarás que te faltan las vocales acentuadas, las letras u con diéresis y las letras eñe.
El mismo problema tendrás si quieres escribir texto en portugués, en francés, en alemán, en ruso, en chino, etc., no tendrás todos los caracteres que necesitas.
Por ese motivo se inventaron otros conjuntos de caracteres, hay un montón de ellos, para contemplar todos los casos posibles. Por ejemplo tenemos al BIG_5 que tiene los caracteres chinos, japoneses y coreanos, el CYRL que tiene los caracteres cirílicos (usados en el idioma ruso), el DOS737 que tiene los caracteres griegos, el DOS862 que tiene los caracteres hebreos, el DOS864 que tiene los caracteres árabes, etc.
Como vimos anteriormente, el conjunto de caracteres ASCII usa solamente los últimos 7 bits de cada byte. Como sobra el bit más significativo entonces se pueden codificar 128 caracteres más. Hay por supuesto muchísimas formas de realizar esa codificación, la más usada es la ISO8859, que tiene varias variantes.
ISO8859_1 tiene todos los caracteres que se necesitan en alemán, danés, español, finés, francés, holandés, inglés, islandés, italiano, noruego, portugués, sueco. Por ese motivo normalmente se lo llama «europeo occidental» o también «Latin 1».
ISO8859_2 tiene todos los caracteres que se necesitan en checo, croata, eslovaco, esloveno, húngaro, polaco, rumano, serbio. Por ese motivo se lo llama «europeo central» o también «Latin 2».
Hay muchos ISO8859 más, que sirven para introducir texto en muchísimos idiomas, pero no en todos. Los idiomas coreano, chino, japonés, etc., no pueden ser usados con ISO8859, ya que esos idiomas tienen más de 128 caracteres distintos.
Pero tener tantos conjuntos de caracteres era muy problemático cuando se quería intercambiar información entre computadoras ¿por qué? porque con los primeros 128 caracteres no había problemas pero con los demás sí. Por ejemplo, con un conjunto de caracteres el carácter ubicado en la posición 163 era la ú (una letra u minúscula acentuada), y con otro conjunto de caracteres en la posición 163 estaba la letra griega mu. Misma posición, distinto símbolo. Muy complicado.
Por ese motivo se decidió inventar un conjunto de caracteres universal, que sirviera siempre y para todos los casos.
A ese estándar universal se le llamó UNICODE.
Mediante UNICODE se puede escribir texto en cualquier idioma conocido, tanto moderno como antiguo, pero además puedes utilizar símbolos especiales matemáticos, notas musicales, flechas, iconos, etc. Eso es posible porque con UNICODE pueden usarse hasta 4 bytes. Si se usaran todos los bits para representar caracteres entonces podríamos tener 2 elevado a la 32, o sea 4.294.967.296 caracteres distintos pero no es así, algunos caracteres son de control, por lo que en realidad solamente se pueden codificar hasta 1.114.112 caracteres distintos, de todas maneras más que suficientes para todas nuestras necesidades actuales y futuras.
Algo que debes recordar es que UNICODE no está terminado, en cada nueva versión se le agregan más símbolos. Pero no te preocupes, ya tiene todos los caracteres usados en todos los lenguajes conocidos, lo que se le va agregando son símbolos. Por ejemplo el símbolo del euro se le agregó en el año 1998, antes de eso no lo tenía porque no podían adivinar que existiría una moneda llamada euro ni cual sería su símbolo.
Cuando en UNICODE se codifican los bits para representar caracteres, hay 3 formas usuales de hacerlo, todas ellas empiezan con las letras UTF (Unicode Transformation Format), y son: UTF-8, UTF-16, UTF-32.
Los números indican cuantos bits se usan en cada grupo de caracteres, no cuantos bits se guardarán.
¿Y qué tiene que ver todo esto con Firebird?
Que en Firebird todo el texto que se introduce en una columna de tipo CHAR o VARCHAR debe pertenecer sí o sí a un conjunto de caracteres.
Cuando creas una Base de Datos debes especificar cual conjunto de caracteres se usará por defecto en ella.
Si no lo especificas entonces se usará NONE. Lo cual es bueno si todo el texto estará escrito en inglés, pero si no es así entonces tendrás problemas cuando quieras usar la función UPPER(), entre otras cosas.
Ejemplo:
Se creó una Base de Datos y se especificó como conjunto de caracteres a NONE. Luego se creó una tabla llamada TEST con una columna llamada NOMBRE de tipo VARCHAR(40), se le insertaron dos filas a esa tabla, y luego se consultó esa tabla:
INSERT INTO TEST (NOMBRE) VALUES('aeiou AEIOU');
INSERT INTO TEST (NOMBRE) VALUES('áéíóú üÜ ñÑ');
SELECT UPPER(NOMBRE) FROM TEST
El resultado obtenido fue:
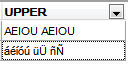
Captura 2. Si haces clic en la imagen la verás más grande
y como puedes ver, las letras del alfabeto inglés sí fueron convertidas a mayúsculas, pero las demás letras no.
Por lo tanto, lo que debemos hacer al crear una Base de Datos es especificar un conjunto de caracteres que contemple todas las letras que se pueden usar en español y que también nos permita ordenar correctamente, y convertir a mayúsculas.
Los dos conjuntos de caracteres más utilizados para lograr ese objetivo son ISO8859_1 y UTF8.
¿Y cuál de ellos es preferible usar?
Es mejor usar ISO8859_1 porque cada carácter siempre ocupa exactamente 1 byte. En cambio si usamos UTF8 cada carácter que no sea ASCII ocupará 2 bytes y estaremos desperdiciando mucho espacio en el disco duro. La excepción a esta regla es si sabes que necesitarás intercambiar datos con bases de datos que usen conjuntos de caracteres que no sean europeos occidentales, por ejemplo con algún ucraniano o algún ruso. Pero para la gran generalidad de los casos, tu mejor opción es usar ISO8859_1.
¿Se puede cambiar el conjunto de caracteres de una Base de Datos?
Supongamos que al crear tu Base de Datos especificaste a UTF8 como su conjunto de caracteres y luego quieres cambiarlo a ISO8859_1 porque es más conveniente ya que se ahorra espacio, ¿puedes hacerlo?
No directamente con el Firebird, pero sí con algunos programas utilitarios como el IBEScript.
¿Y por qué no se puede con Firebird?
Podrías pensar que sería conveniente tener una alternativa como:
ALTER DATABASE ALTER DEFAULT CHARACTER SET ISO8859_1;
pero tal cosa no existe. ¿Por qué no? Porque en tu Base de Datos podrías tener millones de filas que tienen columnas de tipo CHAR o VARCHAR cuyo conjunto de caracteres debería ser cambiado. Y eso tomará un montón de tiempo. Podrías pensar: «bueno, que deje a las columnas como están y que use ISO8859_1 para el nuevo texto», pero eso provocaría inconsistencias. Por ejemplo, al crear la Base de Datos especificaste un conjunto de caracteres que te permite escribir en chino, luego cambiaste de idea y quieres escribir en español. ¿Y las columnas que ya tienen texto escrito en chino? No pueden ser borradas, ni traducidas por el Firebird ya que esa no es su tarea y no puede traducir de cada uno de los cientos de idiomas a cada uno de los otros cientos de idiomas.
Es por ese motivo que debes ser muy cuidadoso al elegir un conjunto de caracteres, ya que si eliges al equivocado luego será muy problemático cambiarlo. Hay programas utilitarios que te permiten realizar esa tarea pero en bases de datos muy grandes el tiempo que se demorarán se cuenta en muchas horas y quizás hasta en días. No es algo que les tomará un minuto o dos minutos terminar.
Sin embargo, en Firebird 3.0 si se tendrá la opción de cambiar el conjunto de caracteres por defecto. La sintaxis prevista es:
ALTER DATABASE
SET DEFAULT CHARACTER SET <nuevo_conjunto_de_caracteres>
Pero el autor de este blog aún no sabe en que condiciones se podrá realizar, ni cuanto tiempo se demorará la tarea de cambiar el conjunto de caracteres en bases de datos muy grandes.
Algo muy relacionado con el CHARACTER SET es lo que se llama COLLATE, que nos permite especificar como serán ordenados los caracteres. Para el lenguaje español es muy sencillo, siempre debemos elegir ES_ES.
Por lo tanto, al crear una Base de Datos que en sus columnas CHAR y VARCHAR podrá tener cualquiera de los caracteres del idioma español lo que debemos escribir es:
CREATE DATABASE 'MiBaseDatos.FDB'
DEFAULT CHARACTER SET ISO8859_1
COLLATION ES_ES;
Artículos relacionados:
Algo más sobre los conjuntos de caracteres
Funciones útiles con los conjuntos de caracteres
Entendiendo COLLATE
Consultando sin importar mayúsculas ni acentos
El índice del blog Firebird21
El foro del blog Firebird21









Comentarios recientes