La gran importancia de tener backups actualizados supongo que no es necesario recalcar a los profesionales de la Informática. Todos sabemos demasiado bien que si una Base de Datos se daña o se corrompe un backup actualizado salvará la situación.
Y nuestra buena fama profesional.
Ahora la pregunta es: después de tener el backup ¿dónde lo guardamos?
Tradicionalmente se aconsejaba tener siempre dos copias del backup. Una de ellas muy cerca del Servidor y otra muy lejos de él, quizás en otra ciudad.
La copia cercana al Servidor la usábamos si se dañó el disco duro, se corrompió la Base de Datos o algo así. Necesitábamos acceder a esa copia lo más rápidamente posible y por lo tanto debíamos tenerla bien cerca. La copia alejada del Servidor la usaríamos si ocurrió una catástrofe como un incendio, un robo, un atentado terrorista, etc. Entonces, aunque la habitación donde se encontraba el Servidor fue destruida teníamos un backup guardado en lugar seguro (en el domicilio del propietario de la Empresa, por ejemplo).
Esa metodología puede seguir usándose, pero desde hace unos cuantos años tenemos otra alternativa, muy interesante: guardar los backups en la nube. De esta manera obtendríamos las dos ventajas anteriores y de una sola vez: nuestros backups estarían muy cerca (a unos clics de distancia) y en caso de catástrofe no sufrirían daño (porque se encuentran en otras computadoras y posiblemente en otro país). Claro que esto no obvia la necesidad de guardar los backups en dispositivos de almacenamiento a nuestro alcance (CD, DVD, pen-drive, otro disco duro, etc.)
En Internet podemos encontrar muchos sitios gratuitos que permiten el almacenamiento de archivos. Pero el tema no es solamente guardar nuestros archivos en esos sitios sino que también la tarea se realice lo más automáticamente posible, con un mínimo de trabajo de nuestra parte.
En este artículo nos referiremos a dos de esos sitios: DropBox y Mega.
Ambos funcionan de la misma manera:
- Abres una cuenta
- Descargas e instalas un programa
- Determinas cuales son las carpetas que serán sincronizadas
- Todos los archivos que guardes en las carpetas elegidas serán subidos a Internet
- Si necesitas recuperar uno de esos archivos, ingresas al sitio con tu nombre de usuario y contraseña y descargas el archivo
Como ves, todo es muy simple, muy fácil y muy sencillo.
Backup en la nube usando DropBox
Primero, ingresamos al sitio:
https://www.dropbox.com/es/
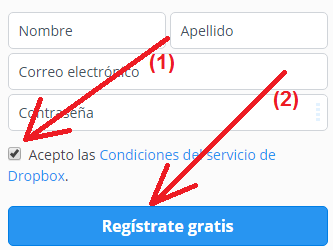
Captura 1. Si haces clic en la imagen la verás más grande

Captura 2. Si haces clic en la imagen la verás más grande
Como nos dice el mensaje, después de finalizada la descarga debemos instalar al Dropbox en nuestra computadora.
Una vez que esté instalado deberemos iniciar sesión.
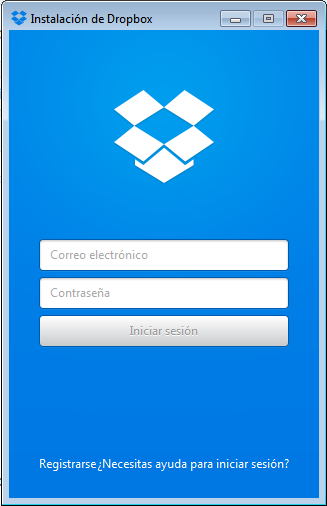
Captura 3. Si haces clic en la imagen la verás más grande
(A veces iniciar sesión se demora algunos minutos, no desesperes, ya se iniciará).
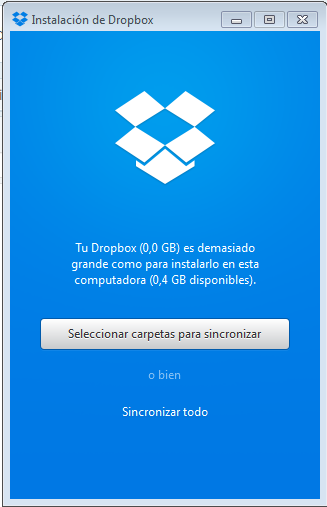
Captura 4. Si haces clic en la imagen la verás más grande
Si ves el cuadro de diálogo de la Captura 4. eso significa que en tu disco C: (que es en donde por defecto sincroniza las carpetas el Dropbox) tienes muy poco espacio. La cuenta gratuita te provee de 2.5 Gb así que en tu disco C: debes tener al menos ese espacio libre.

Captura 5. Si haces clic en la imagen la verás más grande
Si todo está ok, verás la Captura 5.
Para crear la carpeta que por defecto usará el Dropbox debes hacer clic en el botón «Abrir mi carpeta de Dropbox», si prefieres que la carpeta a sincronizar sea otra entonces debes hacer clic en «Configuración avanzada» y verás la Captura 6.
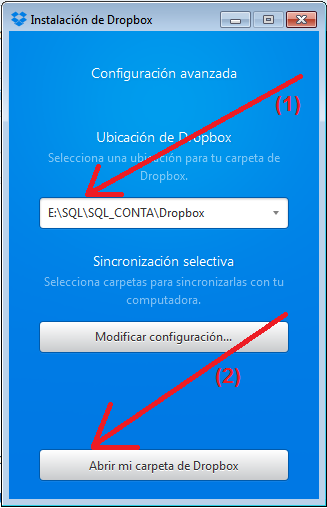
Captura 6. Si haces clic en la imagen la verás más grande
El paso (1) es elegir la carpeta que queremos sincronizar. El paso (2) es abrir esa carpeta para que sea creada.
A partir de este momento, todos los archivos que guardemos en la carpeta elegida, se subirán a Internet. Tendremos así un resguardo seguro para todos nuestros archivos.
Si más adelante queremos cambiar esa carpeta o alguna de las demás opciones del Dropbox entonces hacemos clic en el icono que se encuentra en la barra de tareas del Windows, luego en la ruedita dentada y luego en «Preferencias…»
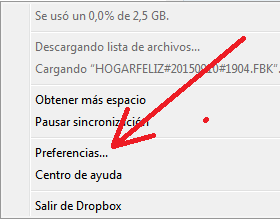
Captura 7. Si haces clic en la imagen la verás más grande
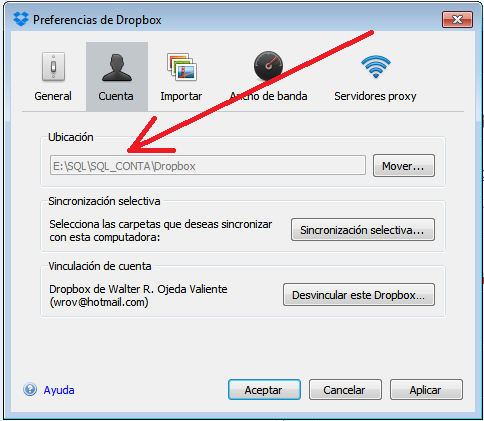
Captura 8. Si haces clic en la imagen la verás más grande
Como habrás notado, un icono del Dropbox se encuentra en la barra de tareas del Windows, haciendo clic en ese icono verás un cuadro de diálogo similar al que te muestra la Captura 9.
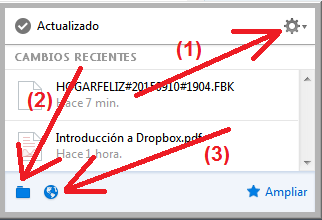
Captura 9. Si haces clic en la imagen la verás más grande
- Si haces clic en (1) verás todas las opciones que tienes disponibles
- Si haces clic en (2) podrás ver la carpeta de Dropbox de tu computadora
- Si haces clic en (3) ingresarás al sitio https://www.dropbox.com/home
Recuperando los archivos:
Cuando necesites recuperar los archivos que tienes guardados en la nube, tienes dos alternativas:
- Hacer clic en (3) de la Captura 9.
- Ingresar al sitio: https://www.dropbox.com/ Luego haces clic en «Inicia sesión», escribes tu e-mail, tu contraseña, y listo.
En ambos casos el Dropbox te mostrará todos los archivos que tienes en la nube, haces clic con el botón derecho sobre el archivo que te interesa descargar y ya está, eso es todo.
NOTA: El Dropbox tiene muchísimas más opciones que si te interesa puedes investigar por tu cuenta. La finalidad de este artículo no es enseñarte a usarlas sino a mostrarte como usando Dropbox puedes tener los backups de tus bases de datos en la nube, de una manera fácil y sencilla y sin ningún trabajo posterior de tu parte (salvo, por supuesto, el de copiar tus archivos de backup en la carpeta sincronizada).
Backup en la nube usando Mega
El sitio https://mega.nz/ ofrece 50 Gb de almacenamiento gratuito (Dropbox solamente 2.5 Gb gratis).
Una vez que ingresamos a ese sitio hacemos clic en el botón «Crear cuenta» que se encuentra en la parte superior de la pantalla, completamos los datos del registro y hacemos clic en el botón «Crear cuenta >» que se encuentra abajo.
Recibirás un e-mail que te pedirá hacer clic en el botón «Activar cuenta».
Después de hacerlo te llevará a una página web donde deberás confirmar tu cuenta.
Una vez confirmada, deberás elegir el tipo de cuenta que te interesa, gratuita o de pago.
Ahora ya puedes subir archivos a esa carpeta, pero de forma manual. O sea que tú deberás elegir cuales archivos deseas subir. Sin embargo, lo mejor es que esa tarea se realice de manera automática. Para ello debemos descargar e instalar el Cliente de Sincronización de Mega.

Captura 10. Si haces clic en la imagen la verás más grande
Una vez finalizada la descarga y la instalación del Cliente de Sincronización de Mega, veremos un cuadro de diálogo como el que nos muestra la Captura 11.

Captura 11. Si haces clic en la imagen la verás más grande
Como ya habíamos creado una cuenta de Mega entonces hacemos clic en el botón «Siguiente», en la siguiente pantalla escribimos nuestro e-mail y contraseña, en la siguiente pantalla elegimos «Sincronización selectiva» (porque si nuestro disco duro es de gran capacidad tardará una eternidad en subirlo a la nube)

Captura 12. Si haces clic en la imagen la verás más grande
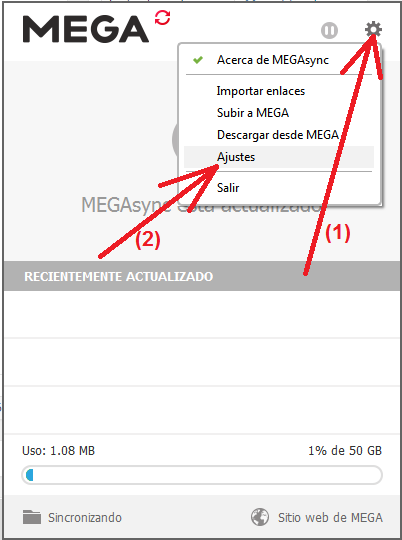
Captura 13. Si haces clic en la imagen la verás más grande
En la barra de tareas del Windows verás el icono de Mega. Haciendo clic en él se muestra un cuadro de diálogo similar al de la Captura 13. Eligiendo la opción «Ajustes» se tienen las opciones disponibles. La más interesante es «Sincronizando» porque nos permite agregar todas las carpetas que queremos sincronizar.

Captura 14. Si haces clic en la imagen la verás más grande
A partir de este momento, todos los archivos que coloquemos en las carpetas locales que se muestran en la Captura 14. se subirán a Internet, automáticamente.
Podemos tener muchas carpetas y muchos archivos en cada una de esas carpetas. Los archivos pueden ser de cualquier tipo. El único requisito es que su tamaño total no debe superar la capacidad de nuestra cuenta (que en el caso de ser gratuita es de 50 Gb.)
Recuperando los archivos
Ok, ya hemos instalado el Cliente de Sincronización de Mega, ya hemos elegido las carpetas que deseamos sincronizar y ahora queremos recuperar alguno de esos archivos. ¿Cómo lo hacemos?
- Ingresamos al sitio: https://mega.nz/ (escribiendo esa dirección en el navegador o haciendo clic en el icono de la barra de tareas del Windows)
- Hacemos clic en el botón «Iniciar sesión»
- Escribimos nuestro e-mail y nuestra contraseña
- Veremos los nombres de las carpetas que hemos creado. Haciendo clic sobre ellas veremos los archivos que contienen
- Haciendo clic con el botón derecho sobre el nombre de un archivo veremos un menú contextual que nos permitirá descargar a ese archivo.

Captura 15. Si haces clic en la imagen la verás más grande
Como ves, simple, fácil, sencillo, sin complicaciones.
Conclusión:
Tener backups actualizados es de suma importancia porque es la forma más rápida y más segura de recuperar datos si ocurre algún problema.
Desde hace unos años tenemos la opción de guardar esos archivos de backup en la nube. Hay muchos sitios que nos permiten eso, dos de los más conocidos son Dropbox y Mega.
Dropbox ofrece 2.5 Gb gratuitos, pero tiene la ventaja de que los archivos pueden ser accedidos desde cualquier dispositivo que pueda conectarse a Internet, no solamente computadoras. Una de sus desventajas es que solamente permite sincronizar a una carpeta, cualquier carpeta que deseemos, pero una sola carpeta.
Mega ofrece 50 Gb gratuitos y tiene la ventaja de que podemos sincronizar muchas carpetas.
MUY IMPORTANTE: Tanto si usamos Dropbox o Mega o cualquier otro sitio de almacenamiento de archivos lo que debemos recordar es que en las carpetas sincronizadas debemos guardar los backups, jamás, pero jamás, debemos guardar en ellas las bases de datos o las corromperemos. NO LO OLVIDES: Si pones una Base de Datos en una carpeta sincronizada, corromperás la Base de Datos.
Artículos relacionados:
¿Se puede usar Dropbox con bases de datos?
Usando MEGA para guardar archivos en la nube
El índice del blog Firebird21
El foro del blog Firebird21





























Comentarios recientes