Lo peor que le puede ocurrir a una Base de Datos operativa es que tenga basura dentro de ella porque en ese caso todas las consultas y todos los procesos dejarán de ser confiables. Se llama «basura» a cualquier dato que está guardado en alguna tabla pero no debería estar allí. La basura puede ser de dos tipos:
- Relacionada con filas
- Relacionada con columnas
Basura relacionada con filas
Estas se producen cuando dos o más filas tienen los mismos datos, es decir se tienen filas duplicadas; o cuando alguna fila tiene NULL en todas sus columnas.
¿Cómo se evita la basura relacionada con las filas?
Con las restricciones Primary Key y Unique Key.
Todas las tablas deben tener una restricción Primary Key, porque de esta manera se podrá identificar a cada fila sin equivocación posible y no se tendrán filas duplicadas totalmente, ya que al menos la Primary Key será diferente.
Cuando se sabe que una fila no admite duplicados, por ejemplo la columna CODIGO_PRODUCTO debe ser única, entonces una restricción Unique Key será la solución.
Sin embargo, a veces no se puede usar una Unique Key aunque se sospecha que puede haber filas duplicadas. Por ejemplo dos clientes pueden tener el mismo nombre, e inclusive el mismo domicilio, el mismo teléfono y la misma localidad porque son padre e hijo y viven en la misma casa.
Entonces aquí lo importante es detectar que hay filas duplicadas. Para ello podríamos escribir una consulta simple que nos indique si tal cosa ocurre:
Listado 1.
SELECT
CLI_NOMBRE,
COUNT(*)
FROM
CLIENTES
GROUP BY
CLI_NOMBRE
HAVING
COUNT(*) >= 2
La consulta del Listado 1. nos mostrará los nombres de todos los clientes que estén duplicados, o sea que se encuentren dos o más veces en la tabla de CLIENTES.
Sin embargo, escribir esa consulta cada vez que deseamos verificar nuestras tablas puede ser muy tedioso, así que la mejor alternativa es crear una vista que nos de esa información y que podamos ejecutar cada vez que lo deseemos.
Listado 2.
CREATE VIEW V_MOSTRAR_DUPLICADOS(
NOMBRE_TABLA,
NOMBRE,
CANTIDAD_DUPLICADOS)
AS
SELECT
'CLIENTES' AS NOMBRE_TABLA,
CLI_NOMBRE AS NOMBRE,
COUNT(*) AS CANTIDAD_DUPLICADOS
FROM
CLIENTES
GROUP BY
CLI_NOMBRE
HAVING
COUNT(*) >= 2
UNION
SELECT
'GARANTES' AS NOMBRE_TABLA,
GAR_NOMBRE,
COUNT(*) AS CANTIDAD_DUPLICADOS
FROM
GARANTES
GROUP BY
GAR_NOMBRE
HAVING
COUNT(*) >= 2;
La vista V_MOSTRAR_DUPLICADOS nos mostrará de una sola vez a todos los clientes duplicados y también a todos los garantes duplicados. Desde luego que nuestra vista real tendrá a muchas tablas más, en este ejemplo se muestran solamente dos tablas para hacer el Listado 2. corto pero la idea es esa: con una sola vista, y mediante UNION tendremos a todas las filas duplicadas de todas las tablas que nos interesa verificar. Para poder conocer a cual tabla pertenece cada fila, en la primera columna colocamos el nombre de la tabla.

Captura 1. Si haces clic en la imagen la verás más grande
Y listo, ahora solamente nos queda comprobar que esas filas son legítimas o que deben ser eliminadas porque realmente están duplicadas.
Basura relacionada con columnas
Esta es la clase de basura que más comúnmente se encuentra en las tablas mal diseñadas. Ocurre cuando en una columna hay un dato incorrecto.
Por ejemplo, el precio de venta del producto es negativo, o la fecha de la cobranza es anterior a la fecha de la venta, o la cantidad vendida es cero, o la venta no tiene fecha, etc.
¿Cómo se evita la basura relacionada con las columnas?
Tenemos varias herramientas que nos permitirán realizar esa tarea:
- La estructura de la tabla
- Los dominios
- La Primary Key
- Las Foreign Keys
- Los check
- Las Unique Keys
- Los triggers
En la estructura de la tabla podemos determinar que una columna no acepte valores NULL o que tenga un valor por defecto.
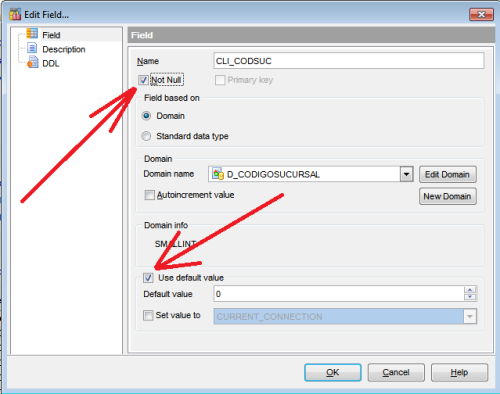
Captura 2. Si haces clic en la imagen la verás más grande

Captura 3. Si haces clic en la imagen la verás más grande
En los dominios podemos determinar los valores, o el rango de valores permitidos.
Captura 4. Si haces clic en la imagen la verás más grande
Captura 5. Si haces clic en la imagen la verás más grande
Con la Primary Key evitamos que esa columna tenga valores NULL o valores duplicados.
Captura 6. Si haces clic en la imagen la verás más grande
Con las Foreign Key evitamos que en una columna se introduzca un valor que no se encuentre en otra tabla. Se usa en las relaciones padre-hija y nos asegura que ambas tablas pueden relacionarse y que en ninguna fila de la tabla hija tengamos un valor que no se encuentre también en una fila de la tabla padre.

Captura 7. Si haces clic en la imagen la verás más grande
Con las restricciones check podemos comparar a dos (o más) columnas de la misma fila e inclusive con columnas de otras tablas.

Captura 8. Si haces clic en la imagen la verás más grande
En la Captura 8. vemos a dos restricciones check. La primera nos asegura que el valor colocado en la columna PRD_CODSUC exista en la tabla de SUCURSALES. ¿Y por qué no usar una Foreign Key aquí? Se podría y se obtendría el mismo resultado pero no sería eficiente ¿Por qué no? Porque las sucursales en general son muy pocas y en Firebird indexar por una columna que tiene muy pocos valores distintos es muy mala idea. Y todas las restricciones Foreign Key sí o sí crean un índice, así que lo recomendable es usar una restricción check que verifique si la sucursal existe o no. La segunda restricción check nos asegura que el precio de venta de un producto siempre sea mayor que su precio de costo.
Las restricciones check se deben cumplir siempre que se quiera insertar (INSERT) o actualizar (UPDATE) una fila. Así que en el ejemplo anterior una fila solamente podrá ser grabada si ambas restricciones check se cumplen.
Con las Unique Key nos aseguramos que nunca dos o más filas puedan tener el mismo valor.
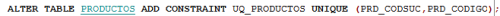
Captura 9. Si haces clic en la imagen la verás más grande
En la Captura 9. vemos que hay una restricción Unique Key sobre las columnas PRD_CODSUC y PRD_CODIGO de la tabla PRODUCTOS. ¿Qué significa eso? Que esa combinación nunca podrá repetirse. En la misma Sucursal no podrá haber dos productos que tengan el mismo código. El Firebird no permitirá que la fila sea grabada, si se quiere hacer algo así.
Los triggers son la herramienta más poderosa que tenemos para evitar que entre basura en una tabla. ¿Por qué? Porque se puede escribir mucho código dentro de ellos. Hasta ahora, las herramientas que habíamos visto eran muy simples, por supuesto que nos ayudaban pero ninguna se compara a la potencia de los triggers.

Captura 10. Si haces clic en la imagen la verás más grande
En la Captura 10. vemos un trigger encargado de validar que el e-mail introducido sea válido. Si el e-mail no es válido entonces se lanza una excepción y por lo tanto no se podrá insertar (INSERT) ni actualizar (UPDATE) esa fila. Eso significa que además de todas las otras restricciones que puedan existir en la tabla de CLIENTES, para que se pueda insertar o actualizar una fila el e-mail debe ser válido.
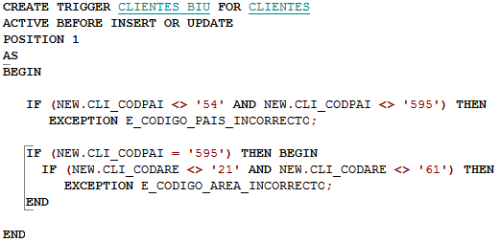
Captura 11. Si haces clic en la imagen la verás más grande
En la Captura 11. el trigger valida que el código del país sea «54» o «595». Cualquier otro código de país será rechazado. Además también valida que en el caso de ser «595» el código del área sea «21» o «61», cualquier otro código de área será rechazado.
Una tabla puede tener muchos triggers, y si aunque sea uno solo de ellos finaliza con una excepción entonces la fila no será grabada en la tabla.
Por consiguiente, para que una fila pueda ser grabada en la tabla todos los triggers, el 100% de ellos, deben finalizar correctamente.
Conclusión:
Lo peor que le puede ocurrir a una Base de Datos operativa es tener basura dentro de ella. ¿Por qué? porque en ese caso ninguna consulta y ningún proceso podrá ser confiable.
Nuestra principal tarea cuando diseñamos una Base de Datos es impedir que entre basura en ella. Si tiene basura, no sirve.
El Firebird nos provee de varias herramientas para ayudarnos con la tarea de evitar a la basura y debemos aprender a usar todas esas herramientas pues para eso están.
La más poderosa de esas herramientas es el trigger, solamente con ella podríamos reemplazar a todas las demás herramientas pero a costa de escribir mucho código. Por lo tanto lo más inteligente es usar a todas las herramientas que tenemos a nuestra disposición y no solamente a los triggers.
Artículos relacionados:
Validando un e-mail
Validando números de teléfono
Asegurando tener datos consistentes en la Base de Datos
La doble validación
Entendiendo a las Foreign Keys
Conceptos sobre las Foreign Keys
Entendiendo las excepciones
Escribiendo un trigger
El índice del blog Firebird21
El foro del blog Firebird21
Escribiendo un trigger




























Comentarios recientes