El lenguaje SQL nos permite agrupar filas. ¿Qué significa agrupar filas? Que todas aquellas filas que tienen en una (o más de una) columna/s valores en común aparecerán una sola vez en nuestra consulta.
Ejemplos:
- Para cada fecha, queremos ver el total vendido en esa fecha.
- Para cada cliente, queremos ver el total vendido a ese cliente.
- Para cada producto, queremos ver la cantidad total vendida de ese producto.
- Para cada vendedor, queremos ver el promedio mensual de ventas de ese vendedor
Hay dos formas de resolver algo así:
- Sin agrupar las filas
- Agrupando las filas
Ventas a un cliente sin agrupar las filas
Tenemos una tabla llamada MOVIMCAB (cabecera de movimientos) donde guardamos los datos de las ventas que realizamos, y si consultamos las ventas realizadas entre el 1 de agosto y el 3 de agosto del año 2015, veremos algo como:

Captura 1. Si haces clic en la imagen la verás más grande
Donde MVC_FECHAX es la fecha de la venta, MVC_IDECLI es el identificador del cliente, MVC_TIPDOC es el tipo de Factura (1=contado, 2=crédito), MVC_NRODOC es el número de la Factura y MVC_TOTALX es el total de esa venta.
Y ahora queremos saber: ¿cuánto le hemos vendido en total al cliente cuyo identificador es 5?. Podemos fácilmente responder a esa pregunta así:
Listado 1.
SELECT
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
WHERE
MVC_IDECLI = 5
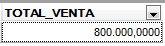
Captura 2. Si haces clic en la imagen la verás más grande
Y como vemos en la Captura 2., funcionó perfectamente. Respondimos muy bien a la pregunta.
Sin embargo, ¿qué pasará si necesitamos conocer el total vendido no a un solo cliente sino a muchos clientes? Que tendremos que repetir el Listado 1. muchas veces, una vez por cada cliente que nos interese. Si tenemos 2000 clientes tendremos que repetir esa consulta 2000 veces, algo totalmente impráctico y mortalmente aburrido.
Hay una solución muchísimo más eficiente: usar la cláusula GROUP BY.
Ventas a los clientes, agrupando las filas
Listado 2.
SELECT
MVC_IDECLI,
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
GROUP BY
MVC_IDECLI
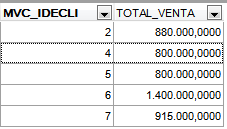
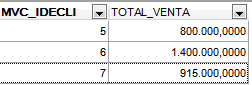
Captura 3. Si haces clic en la imagen la verás más grande
Aquí, para cada cliente, hemos obtenido el monto total vendido, como puedes comprobar mirando la Captura 1. y comparándola con la Captura 3.
Evidentemente, escribir el Listado 2. una sola vez es tremendamente mejor que escribir el Listado 1. unas 2000 veces.
¿Cómo funciona la cláusula GROUP BY?
- Normalmente se la utiliza con las funciones agregadas: COUNT(), SUM(), MAX(), MIN(), AVG()
- Agrupa todas las filas que en una columna (o más de una) columna/s tienen valores en común
- Todas las columnas que no sean funciones agregadas, deben especificarse en la cláusula GROUP BY
Total de ventas, por fechas
En el Listado 2. usamos GROUP BY para obtener el total vendido a cada cliente. Ahora usaremos esa misma cláusula pero para obtener el total vendido en cada fecha.
Listado 3.
SELECT
MVC_FECHAX,
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
GROUP BY
MVC_FECHAX

Captura 4. Si haces clic en la imagen la verás más grande
Y aquí hemos obtenido el total vendido en cada fecha. La diferencia entre el Listado 2. y el Listado 3. es la columna que hemos elegido para agrupar. Al agrupar por identificador del cliente hemos obtenido el total vendido a cada cliente; al agrupar por fecha hemos obtenido el total vendido en cada fecha.
Podemos agrupar por cualquier columna que nos interese. Desde luego que para que tenga sentido en 2 ó más filas esa columna debe tener al menos un valor en común. Por ejemplo, sería una tontería agrupar por la columna MVC_NRODOC ¿por qué? porque no hay valores repetidos allí. Agrupando o no agrupando obtendremos los mismos resultados así que hemos escrito más (porque escribimos la cláusula GROUP BY) y obtuvimos lo mismo que si no la hubiéramos escrito. Pérdida de tiempo.
Por lo tanto, debemos agrupar por cualquier columna que tenga o pueda tener valores repetidos.
Agrupar por varias columnas
En los ejemplos anteriores siempre hemos agrupado usando una sola columna, pero eso no tiene siempre que ser así, podemos agrupar usando varias columnas también.
Por ejemplo, para cada tipo de Factura queremos obtener el total vendido en cada fecha.
Listado 4.
SELECT
MVC_TIPDOC,
MVC_FECHAX,
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
GROUP BY
MVC_TIPDOC,
MVC_FECHAX
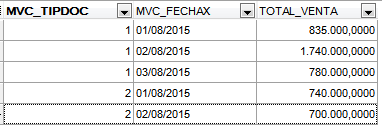
Captura 5. Si haces clic en la imagen la verás más grande
Aquí hemos agrupado primero por MVC_TIPDOC (1=Factura Contado, 2=Factura Crédito) y luego por fecha de la venta.
Así sabemos que el 1 de agosto hubo ventas con Facturas Contado por un total de 835.000 y ese mismo día las ventas con Facturas Crédito ascendieron a 740.000
El Listado 4. nos permitirá responder a: «Muéstrame el total de Facturas Contado vendidas en cada fecha y luego el total de Facturas Crédito vendidas en cada fecha».
Podríamos cambiar el orden, para que primero aparezcan las fechas
Listado 5.
SELECT
MVC_FECHAX,
MVC_TIPDOC,
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
GROUP BY
MVC_FECHAX,
MVC_TIPDOC
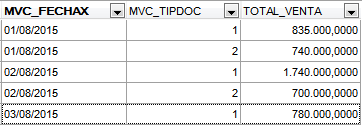
Captura 6. Si haces clic en la imagen la verás más grande
Aunque el orden de las columnas y el orden de las filas está cambiado, vemos que el TOTAL_VENTA sigue siendo correcto. La consulta del Listado 5. nos permitiría responder lo siguiente: «Para cada fecha muéstrame el total vendido con Factura Contado y el total vendido con Factura Crédito».
Un error común de principiantes
Un error muy común entre los principiantes es querer que la consulta muestre también una columna que no fue agrupada. Eso no está permitido, no es posible.
Listado 6.
SELECT
MVC_FECHAX,
MVC_NRODOC,
SUM(MVC_TOTALX) AS TOTAL_VENTA
FROM
MOVIMCAB
GROUP BY
MVC_FECHAX
Si intentamos ejecutar el Listado 6. veremos el mensaje: «Invalid expression in the select list (not contained in either an aggregate function or the GROUP BY clause).«
¿Cuál es el error? Que la columna MVC_NRODOC no se encuentra en la cláusula GROUP BY. Ese SELECT es por lo tanto incorrecto.
Cuando usamos la cláusula GROUP BY al Firebird le estamos pidiendo que agrupe a todas las filas que en una columna (o más de una columna) tenga/n valores repetidos. Para eso sirve la cláusula GROUP BY.
Si en la lista de columnas del SELECT escribimos una columna y a esa columna no la escribimos también en el GROUP BY entonces evidentemente no estaremos agrupando según esa columna. Y no tiene sentido agrupar por algunas columnas sí y por algunas columnas no. O se agrupa por todas las columnas o por ninguna. Agrupar solamente algunas columnas es imposible de realizar.
Si algo así estuviera permitido entonces el Listado 6. nos mostraría una fecha, el número de una Factura (¿de cuál Factura? podemos tener muchas en una fecha), y el total vendido en esa fecha. No nos mostraría la venta de esa Factura sino la venta acumulada de toda la fecha. Eso es un sinsentido. Ninguna pregunta práctica podríamos responder con el Listado 6.
Por ese motivo el Firebird rechazará una consulta como la del Listado 6.
¿Y por qué no agrega a la cláusula GROUP BY todas las columnas que se encuentran en el SELECT?
Podríamos pensar que algo así sería muy práctico: si escribimos una columna en el SELECT y no la escribimos en el GROUP BY, que el Firebird se encargue de agregarla allí.
Bien, eso tiene sus problemas: 1) que el orden de las columnas del SELECT puede ser distinto al orden de las columnas del GROUP BY, no hay obligación de mantener el orden y ya vimos que cambiando el orden de las columnas del GROUP BY se obtienen resultados distintos, por lo tanto el Firebird podría colocar a la columna faltante en el lugar equivocado y no obtendríamos los resultados deseados. 2) Que el Firebird no puede adivinar lo que tú quieres hacer y por lo tanto no puede saber si esa columna sobrante la escribiste por equivocación o si tu equivocación fue no incluirla en el GROUP BY.
En resumen: como con la cláusula GROUP BY se agrupan filas que en una columna (o más de una columna) tiene/n valores repetidos todas las columnas que se escriban en el SELECT deben también, sí o sí, escribirse en el GROUP BY. Eso es lo lógico y lo único que tiene sentido.
Conclusión:
La cláusula GROUP BY es muy útil para agrupar filas que en una columna (o en más de una columna) tienen valores repetidos. Podríamos dejar de usarla y obtendríamos los mismos resultados pero si no la usamos generalmente escribiremos muchísimo pero muchísimo más.
Todas las columnas que escribimos en el SELECT debemos también escribir en el GROUP BY porque de lo contrario obtendremos un error. No tiene sentido tener una columna en el SELECT y no tenerla también en el GROUP BY.
Artículos relacionados:
El índice del blog Firebird21
El foro del blog Firebird21











Comentarios recientes